O algoritmo K-Nearest Neighbors (KNN) é um dos métodos mais simples e amplamente utilizados no aprendizado de máquina. Ele é baseado na ideia de que coisas semelhantes estão próximas umas das outras. Este artigo explora o conceito do KNN, seu funcionamento, vantagens e desvantagens, e como ele pode ser aplicado em diferentes contextos de aprendizado de máquina.
O que é KNN?
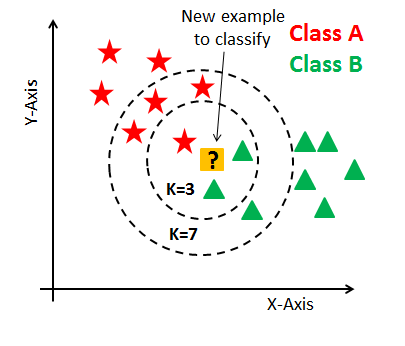
KNN, ou K-Nearest Neighbors, é um algoritmo de aprendizado supervisionado usado tanto para classificação quanto para regressão. Ele opera com base na premissa de que um dado é classificado ou sua saída é prevista com base em quão semelhante ele é aos seus vizinhos mais próximos. “K” refere-se ao número de vizinhos a serem considerados ao tomar uma decisão.
Como Funciona o KNN?
Passos do Algoritmo KNN:
Escolha o valor de K: K é o número de vizinhos mais próximos que serão considerados para classificar ou prever a saída de um dado.
Calcule a Distância: Para cada ponto no conjunto de dados, calcule a distância entre esse ponto e o ponto em questão. A distância pode ser calculada de várias maneiras, sendo a mais comum a distância Euclidiana.
Encontre os K Vizinhos Mais Próximos: Selecione os K pontos no conjunto de dados de treinamento que estão mais próximos do ponto em questão.
Vote ou Calcule a Média:
- Para classificação: Cada um dos K vizinhos vota em sua classe e a classe mais votada é atribuída ao ponto em questão.
- Para regressão: A média (ou outra medida central) dos valores dos K vizinhos é calculada para determinar a previsão.
Aplicações do KNN
Classificação
No contexto da classificação, o KNN é utilizado para categorizar um novo dado com base na maioria dos K vizinhos mais próximos no espaço de atributos. Um exemplo clássico é a classificação de espécies de plantas, onde se utiliza atributos como comprimento e largura das pétalas e sépalas para determinar a espécie.
Regressão
Na regressão, o KNN é utilizado para prever um valor numérico com base nos valores médios dos K vizinhos mais próximos. Por exemplo, o KNN pode ser usado para prever o preço de uma casa com base em características semelhantes (como área, número de quartos, localização).
Vantagens do KNN
- Simplicidade: O KNN é fácil de entender e implementar.
- Versatilidade: Pode ser usado tanto para problemas de classificação quanto de regressão.
- Eficácia em Dados Pequenos: Funciona bem com conjuntos de dados pequenos e onde a relação entre os atributos é bem definida.
Desvantagens do KNN
- Custo Computacional: Pode ser computacionalmente caro, especialmente para grandes conjuntos de dados, já que calcula a distância para todos os pontos de dados.
- Necessidade de Armazenamento: Requer armazenamento de todos os dados de treinamento.
- Sensibilidade a Outliers: Pode ser sensível a outliers, que podem distorcer a classificação ou a regressão.
- Dependência da Escolha de K: A escolha do valor de K pode impactar significativamente o desempenho do modelo. Um K muito pequeno pode levar a um modelo ruidoso, enquanto um K muito grande pode suavizar excessivamente as fronteiras de decisão.
Implementação de KNN
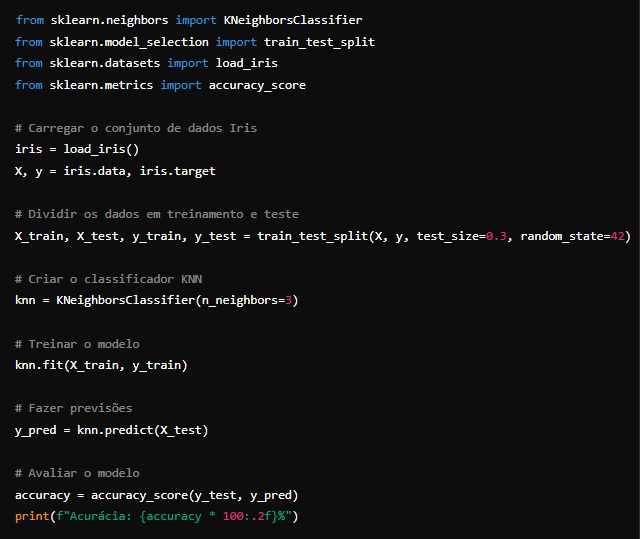
A implementação do KNN pode ser realizada facilmente usando bibliotecas como o Scikit-learn em Python. Aqui está um exemplo simples de como implementar o KNN para classificação:
Conclusão
O KNN é uma técnica fundamental no aprendizado de máquina, conhecida por sua simplicidade e eficácia em muitos cenários. Apesar de suas limitações, como o custo computacional e a sensibilidade a outliers, sua aplicação pode ser extremamente útil em diversas áreas. A escolha do valor apropriado de K e a normalização dos dados são cruciais para melhorar o desempenho do KNN. Com ferramentas modernas como o Scikit-learn, a implementação e experimentação com KNN tornaram-se acessíveis, permitindo que tanto iniciantes quanto especialistas aproveitem ao máximo esta técnica robusta.
Em suma, o KNN continua a ser uma ferramenta valiosa no kit de ferramentas de aprendizado de máquina, oferecendo uma abordagem intuitiva e eficaz para muitos problemas de classificação e regressão.
